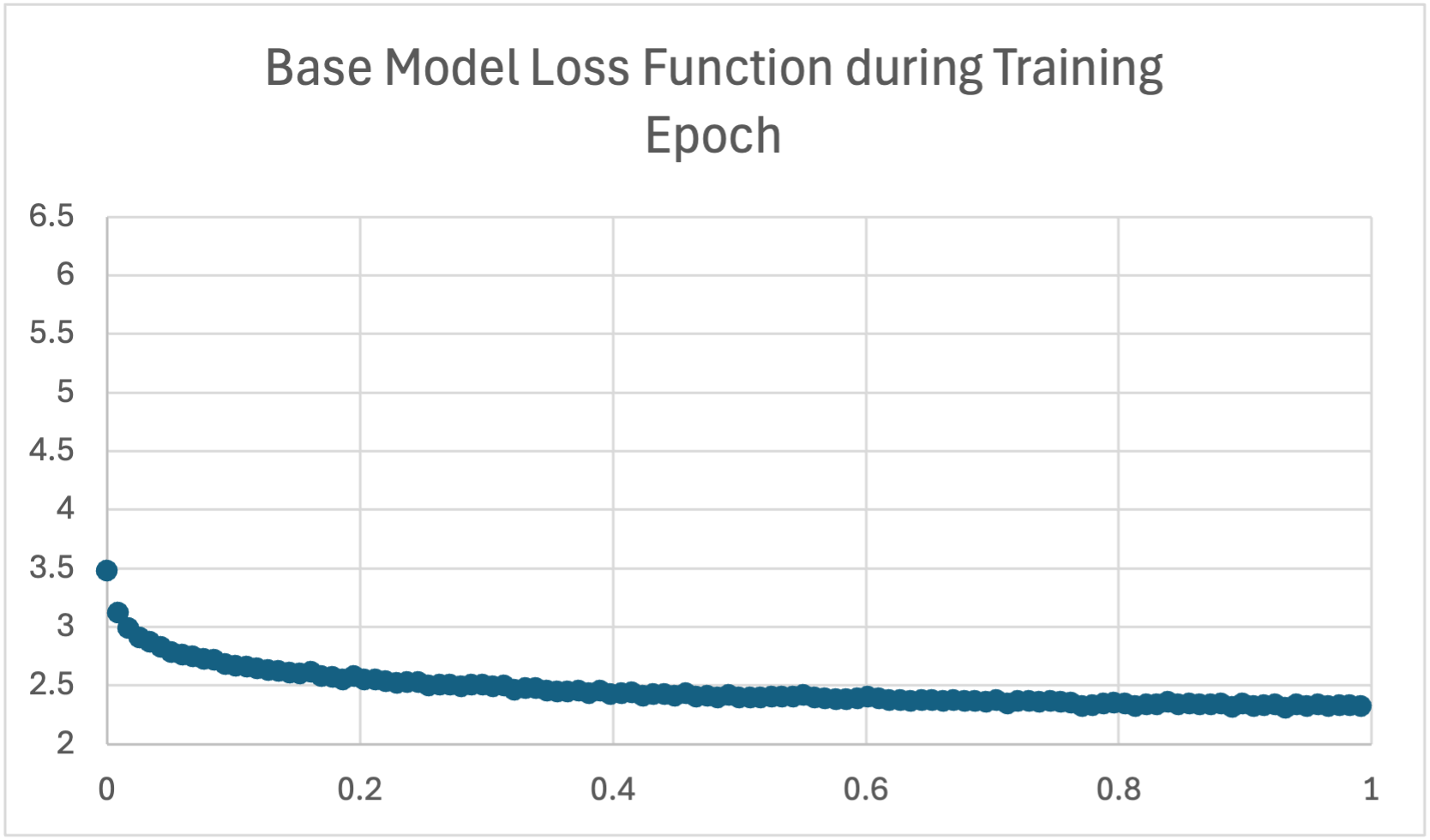
Wikipedia Biography Base Model Training Loss
This graph depicts the training loss of the memory-augmented GPT-2 Medium model on the Wikipedia Biography dataset. Similar to the base model, the loss function shows a rapid initial decrease, followed by a more gradual flattening, indicating effective learning. However, the memory model exhibits a slightly higher starting loss and appears to plateau at a somewhat higher level compared to the base model. This may suggest a higher initial learning curve for the memory-augmented model, but both models demonstrate a general trend of converging loss values.
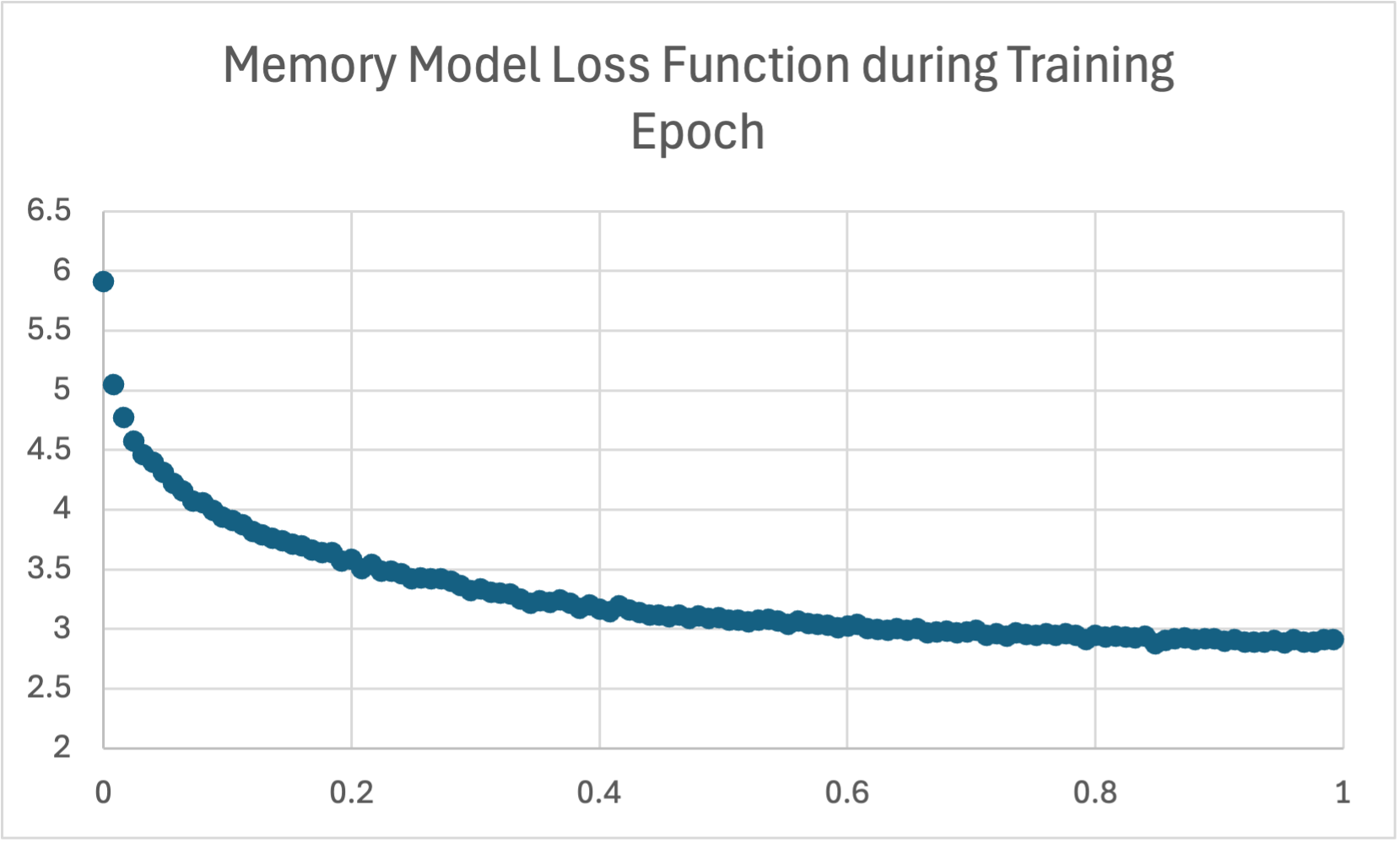
Wikipedia Biography Base Model Training Loss
This graph illustrates the training loss of the base GPT-2 Medium model during training on the Wikipedia Biography dataset. The loss function exhibits a rapid decrease in the initial epochs, demonstrating effective initial learning. Following this sharp decline, the loss continues to decrease, but at a much slower rate, indicating that the model continues to learn and reduce errors, but with diminishing returns as training progresses.
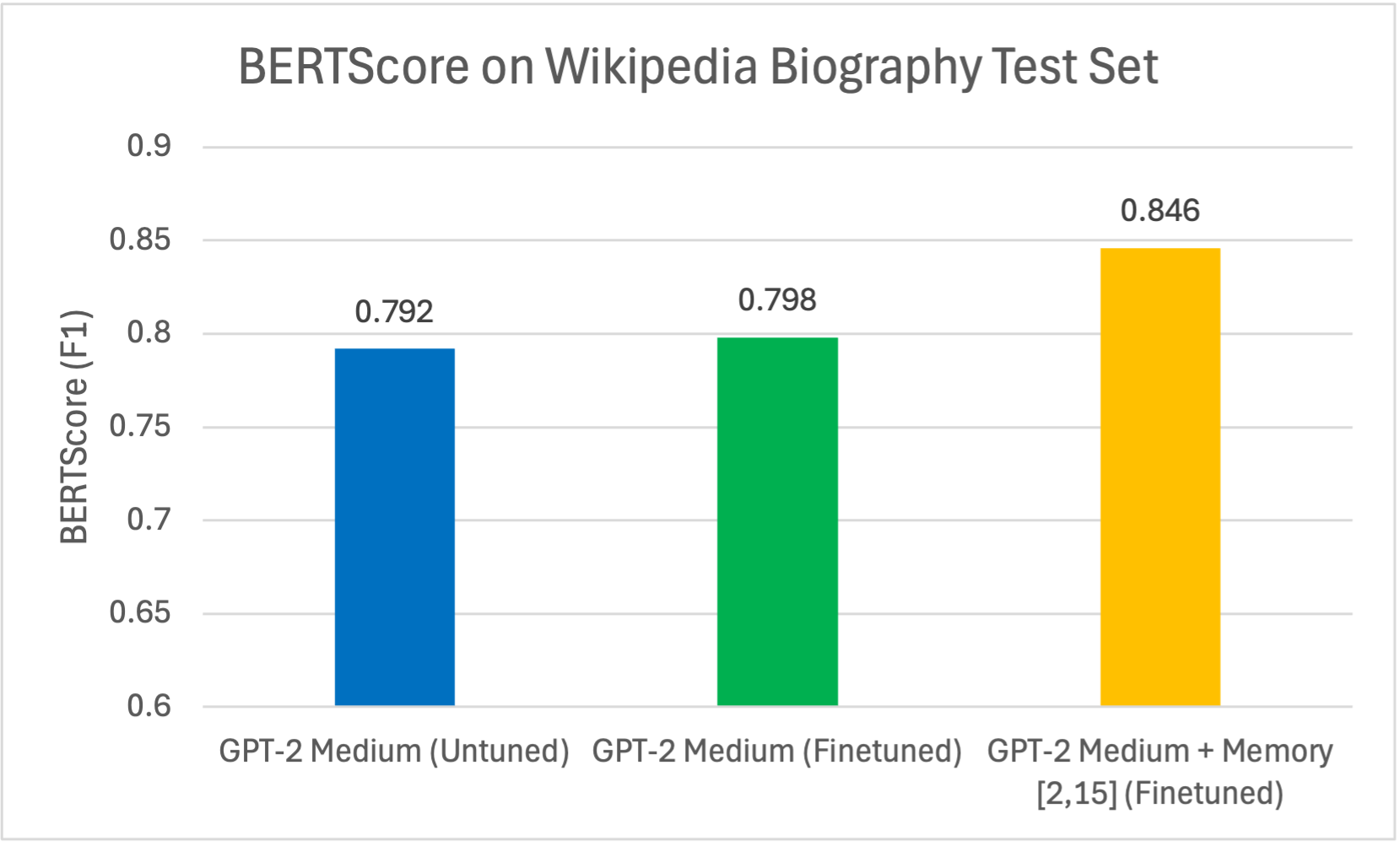
Wikipedia Biography BERTScores
The graph illustrates BERTScore (F1) for Wikipedia biography generation. The fine-tuned GPT-2 Medium model with memory layers (2,15) achieved the highest BERTScore (0.846), outperforming both the fine-tuned GPT-2 Medium baseline (0.798) and the untuned model (0.792). This suggests that incorporating memory layers enhances the model's ability to generate biographies that closely match reference biographies in semantic, contextual, and token-level similarity. This improvement supports the hypothesis that memory layers aid in memorizing and retrieving factual information.
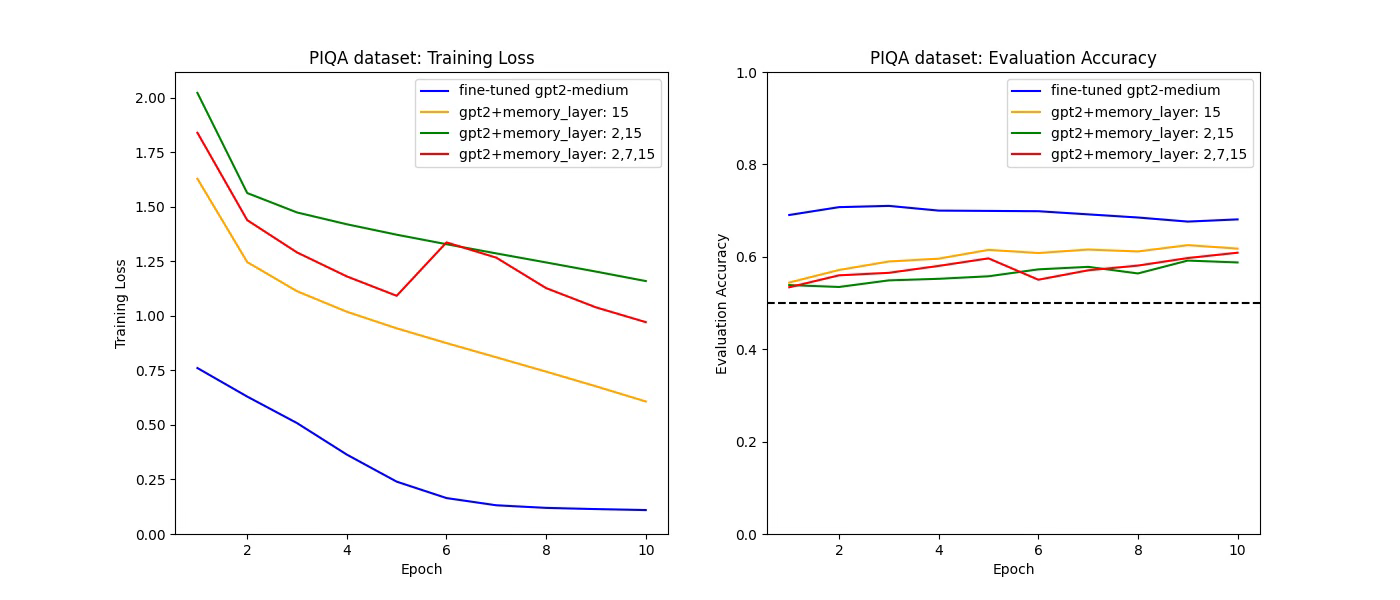
PIQA Training and Evaluation
These graphs depict the training loss (left) and evaluation accuracy (right) of four model configurations over 10 epochs on the PIQA dataset. The fine-tuned GPT-2 Medium model demonstrates the lowest training loss and achieves the highest evaluation accuracy, reaching approximately 0.71 by epoch 3. In contrast, the fine-tuned GPT-2 Medium with memory layers (15) peaks at an accuracy of approximately 0.62 by epoch 10. This data indicates that the addition of memory layers did not enhance the model's performance on the PIQA dataset, with the baseline fine-tuned GPT-2 Medium model showing superior results.
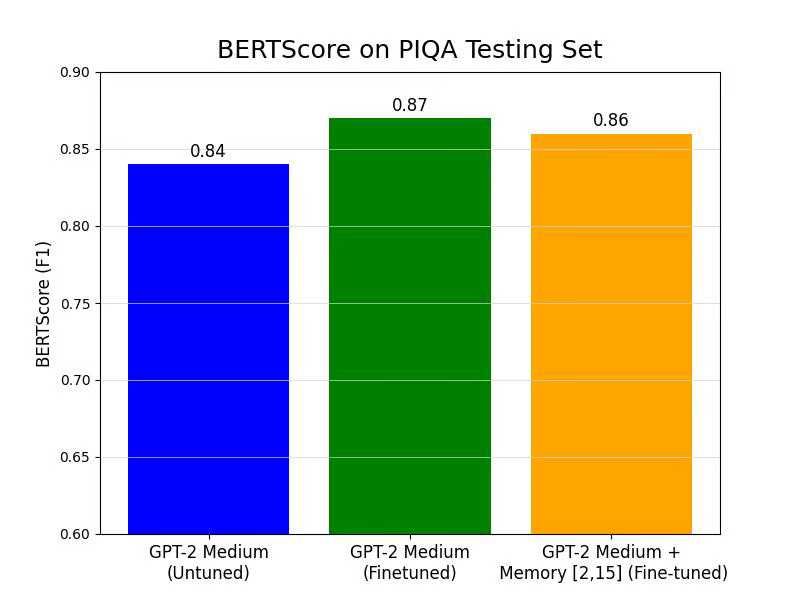
PIQA BERTScores
This graph compares BERTScore (F1) on the PIQA testing set. Contrary to expectations, the fine-tuned GPT-2 Medium model achieved the highest BERTScore, with the fine-tuned GPT-2 Medium with memory layers (15) scoring lower. Specifically, the fine-tuned GPT-2 Medium BERTScore was approximately 0.87, while the fine-tuned GPT-2 Medium with memory layers (15) scored approximately 0.86. This suggests that, for the PIQA dataset, adding memory layers did not improve the semantic similarity and relevance of generated responses compared to the fine-tuned baseline.